Cookie banners don't just block vision models—they cause them to hallucinate
When a cookie banner is on screen at the moment you screenshot a webpage and feed the screenshot to a vision model, the model often doesn't just fail to extract the headlines — it confidently invents plausible-sounding ones. Same page, same model, banner removed: it gets the headlines right.
Across 180 API calls — 9 US news sites, vanilla Chrome vs. Chrome + Ghostery (autoconsent strips the banner), 10 trials per cell — the vanilla model returned 30/90 empty articles arrays (33%). Ghostery returned 0/90 empty (0%). On 5 of 9 sites (theverge, npr, slate, vox, huffpost), the median vanilla trial extracts zero real headlines — either empty, or confabulated entries that don't match anything on the page. On all 9 sites Ghostery extracts real headlines on every trial.
Takeaway, up front: if you ship a vision-based scraping pipeline or browser agent (Operator, Comet, Arc, browser-use, Skyvern, anything that screenshots a page and sends it to an LLM), an autoconsent/adblocker layer is a mandatory pre-processing step. Downstream code can't tell hallucinated headlines from real ones because the JSON is well-formed either way.
See it happen: slate.com
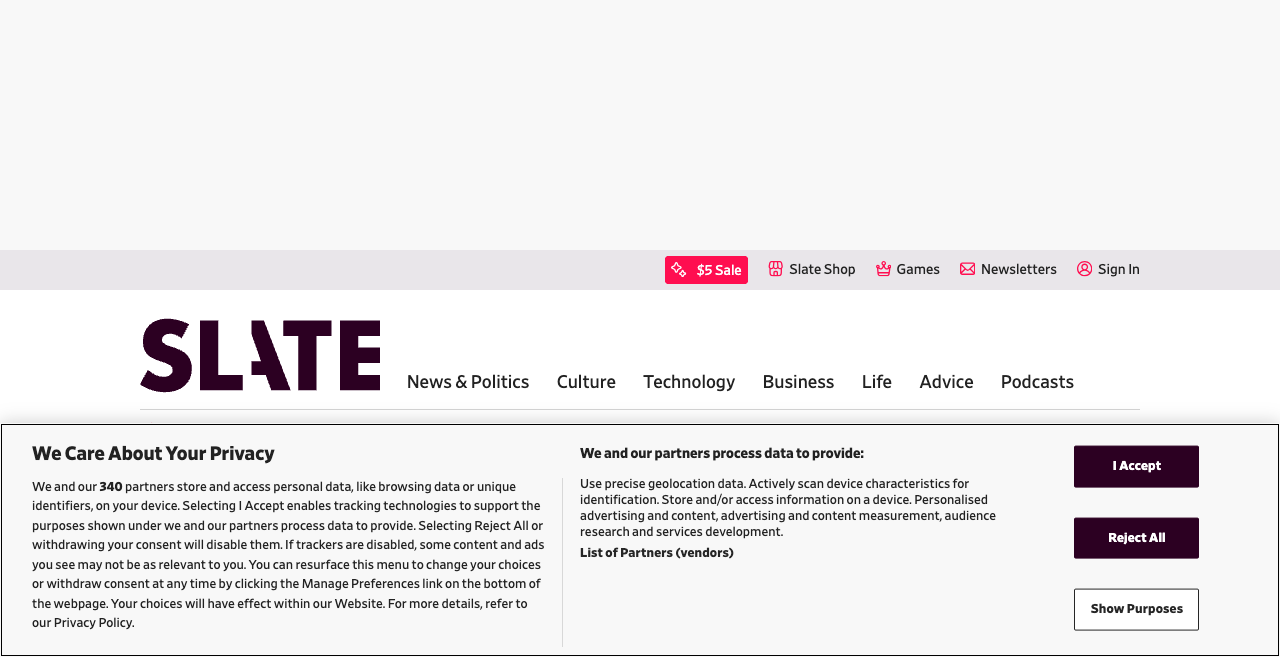
{
"articles": [],
"navigation": [
"News & Politics",
"Culture",
"Technology",
"Business",
"Life",
"Advice",
"Podcasts"
],
"other": [
"$5 Sale",
"Slate Shop",
"Games",
"Newsletters",
"Sign In",
"We Care About Your Privacy",
"We and our partners process data to provide:",
"We and our 340 partners store and access personal data, like browsing data or unique identifiers, on your device...",
"Use precise geolocation data. Actively scan device characteristics for identification..."
...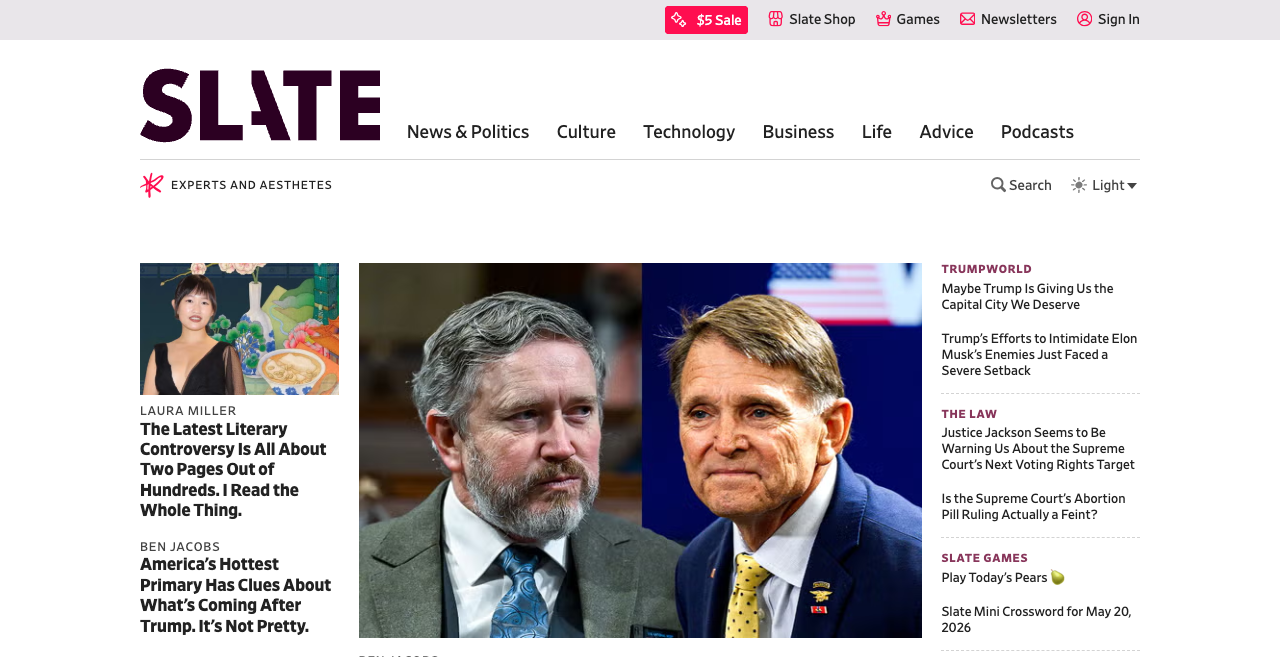
{
"articles": [
"The Latest Literary Controversy Is All About Two Pages Out of Hundreds. I Read the Whole Thing.",
"America's Hottest Primary Has Clues About What's Coming After Trump. It's Not Pretty.",
"Maybe Trump Is Giving Us the Capital City We Deserve",
"Trump's Efforts to Intimidate Elon Musk's Enemies Just Faced a Severe Setback",
"Justice Jackson Seems to Be Warning Us About the Supreme Court's Next Voting Rights Target",
"Is the Supreme Court's Abortion Pill Ruling Actually a Feint?",
"Play Today's Pears 🍐",
"Slate Mini Crossword for May 20, 2026"
],
"navigation": [
"$5 Sale",
"Slate Shop",
"Games",
"Newsletters",
"Sign In",
"News & Politics",
"Culture",
"Technology",
"Business",
"Life",
"Advice",
"Podcasts"
],
"other": [
"EXPERTS AND AESTHETES",
"Search",
"Light",
"LAURA MILLER",
"BEN JACOBS",
"TRUMPWORLD",
"THE LAW",
"SLATE GAMES"
]
}Same Slate homepage, same Anthropic Sonnet 4.5 vision model, same prompt — 10 trials on each variant. Vanilla Chrome: the model returned an empty array on 7 of 10 trials, fabricated content on the other 3. Chrome + Ghostery: the model returned the 6 actual top story headlines on all 10 trials.
What the model hallucinates vs. what's actually on the page
Three illustrative pairs from this run. Vanilla is on the left (fabricated entries from sites where the model returned something under the consent modal). Ghostery is on the right (what the actual top story was, recovered consistently across 10 trials with no banner in the way).
| Site | Vanilla returned (fabricated) | Actual top story (Ghostery returned) |
|---|---|---|
| npr.org | "Defunding public broadcasting doesn't return money to taxpayers" | "Here's how Tuesday's primary elections played out, state by state" |
| theverge.com | "Honda's new EV is a rebranded GM Blazer" | "Valve says games like Vampire Survivors fall under the 'Bullet Heaven' genre" |
| usatoday.com | "New Google CEO Amar Pichawalla: What to know about the new leader" | "US-Cuba tensions escalate amid Raúl Castro indictment: Updates" |
Vanilla returns syntactically valid JSON containing those fake titles. Sundar Pichai isn't named "Amar Pichawalla." NPR's top story isn't about defunding public broadcasting. theverge's top story isn't about Hondas. A pipeline parsing this output has no signal that anything is wrong.
More fabrications from the same run:
- usatoday vanilla also returned "Police say man set three people on fire in Chicago" and "Eric Trump arrested on charges tied to Jan. 6? No, this is a fake photo." Neither was on the page.
- theguardian vanilla repeatedly returned three close-but-different paraphrases of a Stephen Colbert headline ("hosts bid goodbye", "hosts say goodbye", "bids a complicated goodbye") — the real headline is a single different phrasing.
- npr vanilla returned "Cookie Consent & Sponsorship Choices" as an article on one trial. That's the modal title.
Real headlines extracted per inventory call (median across 10 trials)
Per-page numbers
| Page | Variant | Med real headlines (min / max across 10 trials) | Med array length | Zero-article trials |
|---|---|---|---|---|
| theverge | vanilla | 0 (0 / 0) | 0 | 7 / 10 |
| theverge | ghostery | 2 (1 / 3) | 2 | 0 / 10 |
| cnn | vanilla | 3 (1 / 3) | 8 | 0 / 10 |
| cnn | ghostery | 6 (4 / 6) | 7 | 0 / 10 |
| npr | vanilla | 0 (0 / 0) | 1 | 0 / 10 |
| npr | ghostery | 4 (3 / 4) | 4 | 0 / 10 |
| theguardian | vanilla | 2 (1 / 2) | 4 | 0 / 10 |
| theguardian | ghostery | 3 (3 / 3) | 3 | 0 / 10 |
| usatoday | vanilla | 2 (1 / 5) | 5 | 0 / 10 |
| usatoday | ghostery | 6 (3 / 9) | 6 | 0 / 10 |
| slate | vanilla | 0 (0 / 0) | 0 | 7 / 10 |
| slate | ghostery | 7 (6 / 7) | 8 | 0 / 10 |
| vox | vanilla | 0 (0 / 0) | 0 | 6 / 10 |
| vox | ghostery | 1 (1 / 3) | 1 | 0 / 10 |
| huffpost | vanilla | 0 (0 / 0) | 0 | 10 / 10 |
| huffpost | ghostery | 2 (2 / 2) | 3 | 0 / 10 |
| newsweek | vanilla | 4 (4 / 4) | 4 | 0 / 10 |
| newsweek | ghostery | 4 (4 / 4) | 4 | 0 / 10 |
How we counted real headlines
Raw array length isn't a fair quality proxy. CNN's homepage shows two layers of "headlines" — a 7-entry tag-cloud of short labels ("Raul Castro indicted", "Ebola outbreak", "Putin and Xi") and a hero card with full article titles ("94-year-old Castro is charged with conspiracy to kill US nationals, destruction of an aircraft and murder"). Vanilla on CNN reliably extracts the tag-cloud; Ghostery reliably extracts the hero card. By raw array count, the tag-cloud (8 entries) looks better than the hero card (5–7 entries). By usefulness to a downstream consumer, the hero card wins by a mile. On theguardian, vanilla returns four entries that are three near-paraphrases of the same real headline plus one fabrication — four entries, but only one real story.
So we count unique real headlines extracted per trial:
- Build ground truth from Ghostery's repeated extractions. A candidate headline goes into ground truth for a page if it (a) is at least 25 characters long, (b) contains at least 4 meaningful (non-stopword) tokens, and (c) appears in at least 2 of the 10 Ghostery trials. The length filter (a, b) excludes tag-cloud labels like
"Cave divers"or"Ebola outbreak"so the metric measures real article-title extraction rather than label-dumping. The repetition filter (c) excludes one-off Ghostery-side hallucinations. - Fuzzy-match each extracted entry against each ground-truth headline. We tokenize both, drop stopwords, and require at least 50% of the shorter side's tokens to appear in the longer. Under this rule,
"Late-night TV hosts bid goodbye to Stephen Colbert"matches the real"Late-night TV says goodbye to Stephen Colbert"(paraphrase of the same headline), but"Raul Castro indicted"does not match"94-year-old Castro is charged with conspiracy…"(only one common meaningful token, "castro"). - Count unique ground-truth headlines matched per trial. Each ground-truth entry counts at most once per trial, so repeated paraphrases of the same headline collapse into a single match.
Reading the table
- Vanilla extracts zero real headlines (5 of 9 sites — theverge, npr, slate, vox, huffpost): the model either returns an empty array or fills it with fabricated entries that don't match any real headline on the page. Ghostery extracts the actual top stories. Breakdown: theverge (7/10 empty, 2 → 0 real headlines); npr (0/10 empty, 4 → 0 real headlines); slate (7/10 empty, 7 → 0 real headlines); vox (6/10 empty, 1 → 0 real headlines); huffpost (10/10 empty, 2 → 0 real headlines).
- Mixed (cnn, theguardian, usatoday): vanilla returns a mix of real headlines and fabrications. The raw array length looks fine, but only some of the entries map to actual page content; Ghostery returns more distinct real headlines.
- No effect (newsweek): both variants extract roughly the same set of real headlines. The consent banner is small or doesn't visually compete with the article body.
Why the model fails
Two things the modal does to the image push the model away from the article content:
- Physical obstruction. On
slate,huffpost,voxthe modal sits over the upper-fold area and the article hero card is literally not in the pixels. At 1280×800 with the banner up, there's nothing to extract. - Attention hijacking. On
theverge,cnn,usatoday,theguardianthe article content is physically still visible around the edges, but the modal is the visually dominant element. The model's attention concentrates on the high-contrast modal text and the article snippets fade into background.
The strongest evidence for the second mechanism: on npr, the consent banner is bottom-anchored and the page's top headline is fully visible above it in the vanilla viewport. The model still fails — fabricating NPR-style headlines like "Defunding public broadcasting doesn't return money to taxpayers" while the real top story about Tuesday's primaries sits right there in the pixels, unread.
Takeaways — what to do if you ship a vision-based browser pipeline
- Treat banner dismissal as a mandatory pre-processing step, not a "nice to have." Load an autoconsent layer (DuckDuckGo rulebase, Ghostery, Consent-O-Matic, Brave's built-in handling, or hand-rolled CMP-specific dismissers for your target sites) and verify it actually fires — check both the screenshot and the DOM after settle. Rule coverage varies per CMP deployment, and a silently-disabled extension is indistinguishable from no extension at all.
- Add a regression test that asserts "the model returns the page's actual top headlines," not just some
string[]. The methodology in this post is a runnable template: pick 5–10 pages your product cares about, build a small ground-truth list, assert the model recovers ≥N of them. - Watch your output tokens, not just input. Cluttered viewports inflate output-token cost by 30–60% even when extraction succeeds. Image input is fixed (~1,300 tokens for a 1280×800 PNG); the variable cost is on the response side.
- If you can't dismiss the banner, scroll past it before screenshotting. ~600px down usually leaves the article body visible while the banner stays anchored. Worse than dismissal, better than a banner-dominated screenshot.
- Don't trust string-shaped LLM output to be grounded. Even when the JSON parses cleanly, the strings inside can be confabulated. Surface uncertainty downstream — confidence thresholds, second-pass cross-checks, or compare against a content-DOM extraction.
The point isn't Ghostery specifically. The point is that some layer between your headless browser and your model needs to clear the banner, and "no banner clearing" is the silent-default state of every headless Chrome you spin up.
Methodology
Source code, raw API outputs per call, and all 180 screenshots are at ghostery/researches/vlm-cookie-banner-may-2026.
- Model:
claude-sonnet-4-5-20250929, default temperature,max_tokens=2048, one API call per screenshot. - Setup: Chrome for Testing 148 + chromedriver, fresh isolated profile per trial, 5s settle, anti-bot fingerprints suppressed (
navigator.webdriver === false,--disable-blink-features=AutomationControlled) so CMPs serve us the same payload they serve a human. - Pages:
theverge,cnn,npr,theguardian,usatoday,slate,vox,huffpost,newsweek, loaded from a US (San Jose) IP. 9 pages × 2 variants × 10 trials = 180 calls. - Intervention: vanilla Chrome vs. Chrome + an unpacked Ghostery extension built with
npm run build chromium -- --automation(skips onboarding, enables adblocker + autoconsent without a user click). - Prompt: required strict JSON escaping after early parse failures on headlines with nested quotes — 178/180 calls produced syntactically valid JSON in this run.
- Ground truth for matching: built from Ghostery's extractions, keeping headlines that (a) are ≥25 characters, (b) contain ≥4 non-stopword tokens, (c) appear in ≥2 of 10 Ghostery trials. (a) and (b) exclude tag-cloud labels (
"Cave divers","Ebola outbreak"); (c) excludes one-off Ghostery hallucinations. - Fuzzy match: an extracted entry matches a ground-truth headline if ≥50% of the shorter side's meaningful tokens appear in the longer side.
Verbatim prompt:
You are an inventory assistant looking at a webpage screenshot. Identify every visible element and categorize each. Output a single JSON object with these keys:"articles"— an array of plain string headlines (each entry is one headline string, not an object)."navigation"— an array of plain string nav link labels."other"— an array of plain strings for cookie banners, modals, buttons, etc. CRITICAL: every string MUST be valid JSON. Escape any"inside a string as\". Do not output objects, only plain strings. Do not include trailing commas. Be exhaustive within the visible viewport. Output ONLY the JSON object. No commentary, no code fences.
Not a max-tokens crash, not Anthropic-specific, not "you need Ghostery." Caveats: 178/180 calls produced syntactically valid JSON under 2048 output tokens (1 truncation, 1 parse failure — both vanilla npr); GPT vision and Gemini vision will hit the same attention-budget problem with different specific failure shapes; any browser layer that clears the banner before the screenshot will produce the same result Ghostery did here.